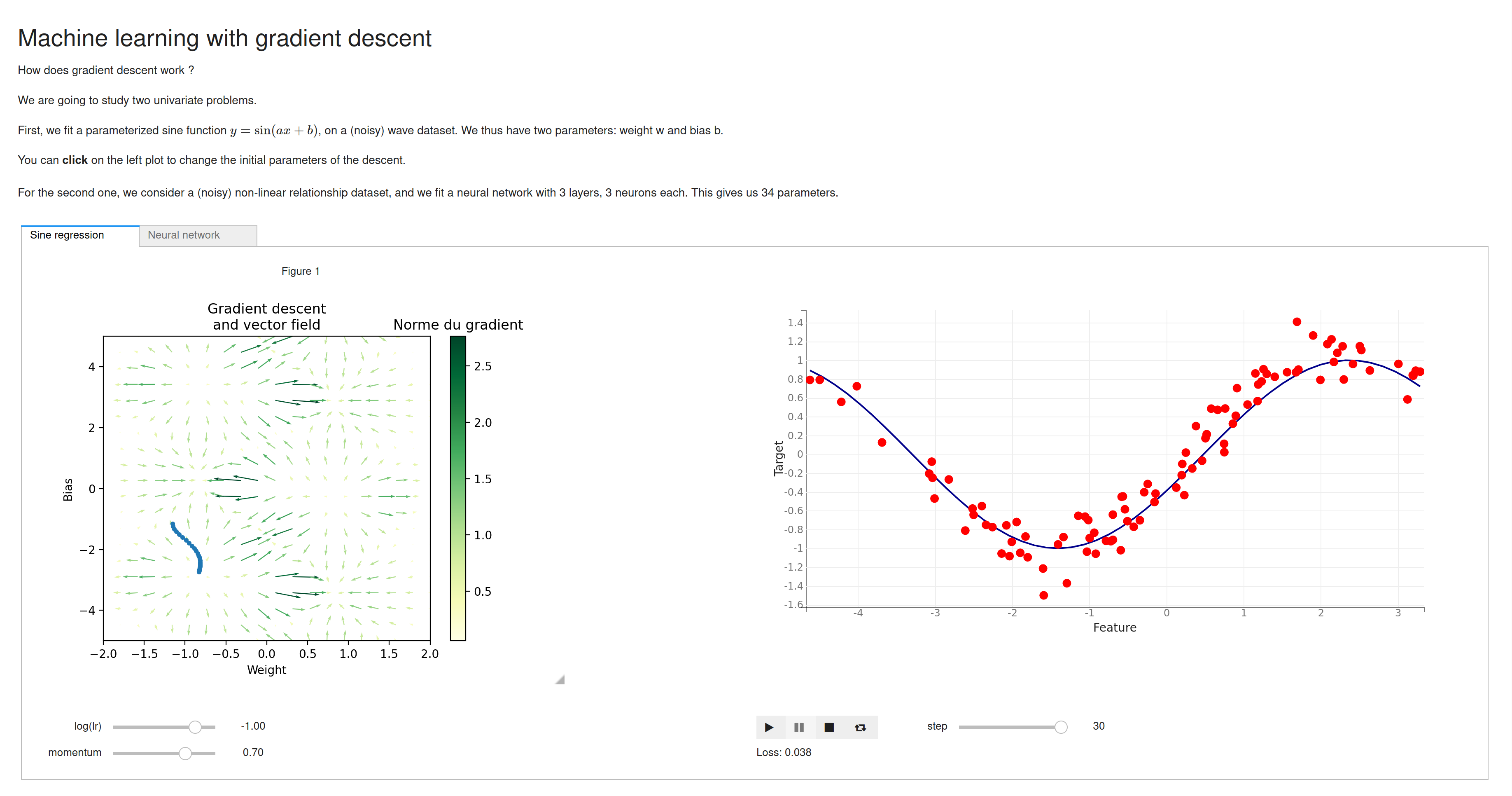
Lately, I have been interested in the foundations of machine learning (ML) in a pedagogical perspective. A first step to grasp the power of ML is gradient descent. So, I was determined to demonstrate the way it works with an interactive app.
Python and Jupyter world
The first thing I made used Jupyter, and a nifty package called Voilà, that turns a notebook into a standalone app. For automatic differentiation, I used vanilla JAX. For the front-end, I used ipywidgets, bqplot and matplotlib [^ipympl].
Bqplot is amazing for classic plots, plays very well with ipywidgets for reactivity. I was unable to find a way to make it display a vector field nicely though, so I had to use interactive matplotlib, which is heavier and slower, to display the gradient of the loss.
I deployed this on Heroku with a small Procfile:
web: voila --port=$PORT --no-browser techni.ipynbAnd boom! It was live!
Speed of light
In this setting, every state change triggers a round-trip to the server, through websockets (Jupyter is based on Tornado). Locally, this works great since there is zero latency between my computer and my browser (running on… my computer).
However, whenever I browsed the Heroku-hosted app, there were significant lags. There is now a latency due to the speed of light through the wire, which ranges from 100ms to 600ms depending on your region of the world.
Svelte to the rescue
I needed a proper front-end, so that every action on the client does not require a round-trip to the server. I also would have more control over how to react once a new payload is sent from the server.
Moreover, the dataviz I made were functional and did a good job of explaining the concept. However, they were a bit primitive: no transition nor interpolation between distinct states, which provides a bit of a boorish experience.
I decided to leverage the new hot JS framework Svelte, with reactivity built-in. So, I surgically removed the JAX bits of the code and moves them to a back-end built with FastAPI, that the Svelte front-end calls. The front-end is hosted on Cloudflare pages, and calls the API whenever the hyperparameters of the descent are modified.
For plotting, I used the experimental pancake library by the creator of Svelte, Rich Harris. Thanks to Svelte tweened and spring motion functions, the transitions are smooth and easy on the eyes.

Going world-scale
There is a shortcoming of this setting: the latency is still there. It is handled in a better way with async javascript, but if the API is hosted in, say Frankfurt, then a user in Sydney is not going to have a very snappy experience.
I was wondering: could it be possible to replicate the backend in a few data centers, and route users to the closest one in order to minimize the latency? Well, after a few days of research I found that this is exactly what Fly provides. So, I went a bit crazy and replicated the back-end in 10 regions and thoroughly tested the latency with a VPN (accounting for the additional round-trips). It seemed to work well enough!
Now I had
- A front-end replicated on a CDN on 200+ locations
- A back-end replicated at 10 locations
At this point, you might think that this is a tad overkill for a simple pedagogical app, and I don’t think you would be very wrong.
To the browser: TensorflowJS
I ported the JAX code to TensorflowJS, on Observable at first and then directly in the Svelte front-end. Now I have a fully client-side app: no server, yay !?
For the fast 30-step gradient descent, this works great and the computing happens instantly. However, when I add a simple neural network, I hit the performance wall: what takes 5ms in (already JIT-compiled) JAX, takes 300ms in the browser! yay…
Reuse
Citation
@online{guy2021,
author = {Guy, Horace},
title = {The Need for Speed},
date = {2021-09-03},
url = {https://blog.horaceg.xyz/posts/need-for-speed/},
langid = {en}
}